Back to selected work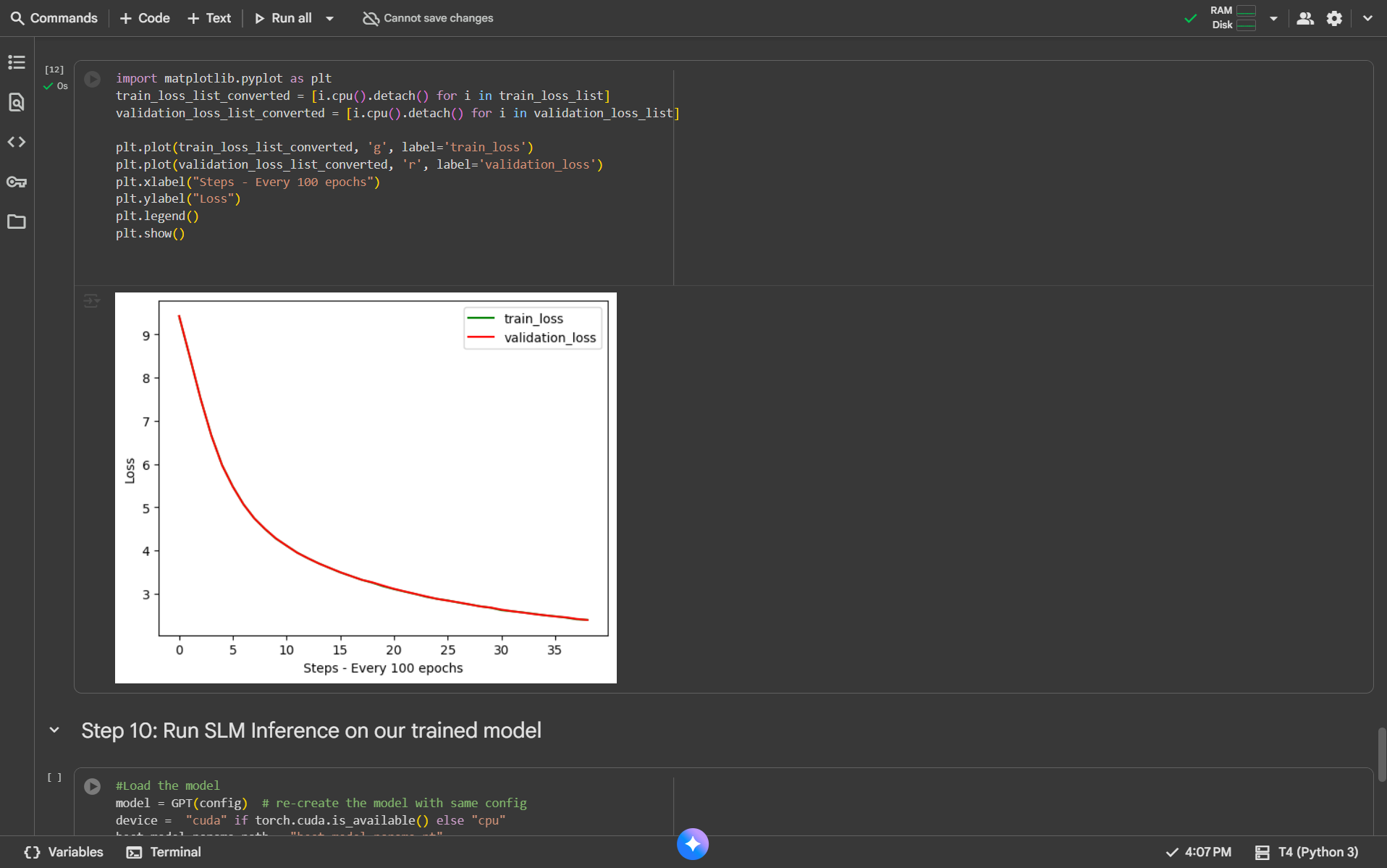
Small Language Model From Scratch - TinyStories
A small transformer built from scratch to understand every layer before trusting higher-level abstractions.
Loss CurveConverged at 2.1 validation loss
RoleResearch engineer
StatusOpen source
StackPyTorch / Python / Custom BPE / AMP / mmap
Problem
Most learning paths hide the model behind libraries. This project forced the complete training pipeline into the open: tokenization, batching, transformer blocks, optimization, sampling, and failure modes.
Architecture
Text CorpusTinyStories
Custom BPE TokenizerNo borrowed tokenizer
Transformer x6Attention, MLP, LayerNorm
AMP Training LoopWarmup and cosine schedule
SamplingTemperature and top-k generation
Key Decisions
No pre-trained weights
The point was not leaderboard performance. The point was to understand how a transformer learns when every part of the pipeline is visible.
Custom tokenizer before model training
Building the tokenizer made subword segmentation concrete and exposed how vocabulary choices affect the model's behavior.
Mixed precision as practical systems work
AMP reduced memory pressure enough to make useful experiments possible on limited hardware without changing the core learning objective.
Lessons / Results
- Training quality is often decided by data handling and optimization details, not only model size.
- The attention block becomes less mystical when you have made it fail yourself.
- A small model is a better teacher than a black-box frontier API.
Theoretical Foundation
Proof Links
© 2026 Pranav Dhiran
Contact